Choose an SQL Table Storage Layout
In InterSystems IRIS®, a relational table, such as the one shown here, is a logical abstraction. It does not reflect the underlying physical storage layout of the data.
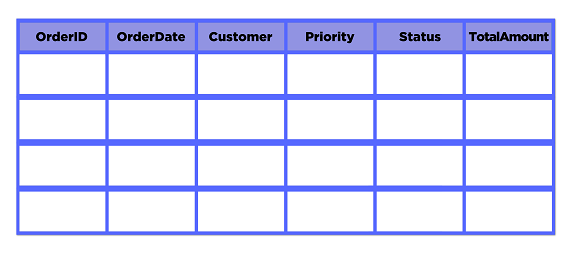
Using the flexibility inherent to globals, the lower-level InterSystems IRIS storage structure, you can specify whether to store the data in rows, columns, or a mixture of both. Depending on the size of your data and the nature of your queries and transactions, making the right storage layout choice can increase query performance or transaction throughput by an order of magnitude.
The choice of storage format has no effect on how you author your queries and other SQL statements, such as INSERTs. It is complementary to other table-level storage options such as sharding, which can further improve query performance for large tables. You can also define indexes on tables of any storage layout to gain additional performance benefits. For more details, see the Indexes on Storage Layouts section.
This table summarizes the row-based and column-based (columnar) storage formats.
| Row Storage (Default) | Columnar Storage |
|---|---|
|
Primary data is stored in one global. Each row of data is stored in a separate global subscript, using a list encoding that supports elements with different data types. In general, transactions affect individual rows and process efficiently on data stored by row, but analytical queries might be slower. |
Primary data is stored in one global per column. Sequences of 64,000 data elements are stored in separate global subscripts. Data is encoded using a vector encoding that is optimized for storing elements of the same data type. In general, analytical queries run quickly but transactions might be slower. |
 |
 |
|
Use row storage for:
|
Use columnar storage for:
|
Choosing a storage layout is not an exact science. You might need to experiment with multiple layouts and run multiple query tests to find the optimal one. For more of an overview on deciding between row and columnar storage layouts, along with sample use cases for choosing each layout, see the What Is Columnar Storage?Opens in a new tab video.
Once you define a storage layout for your data, you currently cannot change it without reloading the data.
Row Storage Layout
When you define a table, either in the InterSystems SQL DDL language or in a persistent class, InterSystems IRIS defaults to using row storage.
Define Row Storage Table Using DDL
In InterSystems SQL DDL, the CREATE TABLE command defines tables in a row storage layout by default. CREATE TABLE does provide an optional WITH STORAGETYPE = ROW clause that you can specify after the column definitions, but it can be omitted. These two syntaxes are equivalent:
CREATE TABLE table ( column type, column2 type2, column3 type3)
CREATE TABLE table ( column type, column2 type2, column3 type3) WITH STORAGETYPE = ROW
The following CREATE TABLE command creates a table of bank transactions. The table contains columns for the account number, transaction date, transaction description, transaction amount, and transaction type (for example, "deposit", "withdrawal", or "transfer"). Since the WITH STORAGETYPE clause is omitted, the table defaults to row storage.
CREATE TABLE Sample.BankTransaction (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2),
Type VARCHAR(10))Define Row Storage Table Using a Persistent Class
As with tables created using DDL, tables created by using a persistent class also use the row storage layout by default. You can optionally define the STORAGEDEFAULT parameter with the value "row" or the empty string (""), but both can be omitted. These syntaxes are equivalent:
Parameter STORAGEDEFAULT = "row";
Parameter STORAGEDEFAULT = ""; /* Or can be omitted entirely */
The following persistent class shows the definition of a row storage table similar to the DDL-defined table created in the previous section. The USEEXTENTSET parameter organizes the table storage into a more efficient set of globals. The bitmap extent index creates an index of all IDs in the extent set, which makes counting and other operations more efficient. When you define a table using DDL commands, InterSystems SQL applies these settings automatically and includes them in the projected persistent class. For more details, see Defining a Table by Creating a Persistent Class.
Class Sample.BankTransaction Extends %Persistent [ DdlAllowed ]
{
Parameter USEEXTENTSET = 1;
Property AccountNumber As %Integer;
Property TransactionDate As %Date;
Property Description As %String(MAXLEN = 10);
Property Amount As %Numeric(SCALE = 2);
Property Type As %String(VALUELIST = ",Deposit,Withdrawal,Transfer");
Index BitmapExtent [ Extent, Type = bitmap ];
}
The DEFAULT in the parameter name STORAGEDEFAULT implies that InterSystems IRIS uses this parameter value as the default when generating storage definition entries for this class. As with most class parameters that impact storage, such as USEEXTENTSET and DEFAULTGLOBAL, this value is considered only when generating storage, upon the initial compilation of the class or when adding new properties. Changing these parameters for a class that already has a storage definition (saved in a Storage XData block) has no effect on that storage, including on data already stored for the class extent.
Row Storage Details
In a table with row storage, all data is stored in a single global. Each subscript of this global contains a $LIST value that stores the data for a single row of table column values. The $LIST data type stores elements of varying types and encodes empty string (' ') and NULL values efficiently. These characters make $LIST suitable for storing rows of data, where columns usually have varying types and might contain NULL values.
Suppose the BankTransaction table from the previous section contains these transaction records:
SELECT AccountNumber,TransactionDate,Description,Amount,Type FROM Sample.BankTransaction| AccountNumber | TransactionDate | Description | Amount | Type |
|---|---|---|---|---|
|
10001234 |
02/22/2022 |
Deposit to Savings |
40.00 |
Deposit |
|
10001234 |
03/14/2022 |
Payment to Vendor |
-20.00 |
Withdrawal |
|
10002345 |
07/30/2022 |
Transfer to Checking |
-25.00 |
Transfer |
|
10002345 |
08/13/2022 |
Deposit to Savings |
30.00 |
Deposit |
You can optionally examine the global storage structure from the Management Portal by clicking System Explorer and then Globals. In the namespace containing the table, you can then select Show SQL Table Name and find the Data/Master global corresponding to your table. For more details, see Managing Globals. This code shows a sample Data/Master global that is representative for most standard tables on InterSystems IRIS.
^BankT = 4
^BankT(1) = $lb(10001234,66162,"Deposit to Savings",40,"Deposit")
^BankT(2) = $lb(10001234,66182,"Payment to Vendor ABC",-20,"Withdrawal")
^BankT(3) = $lb(10002345,66320,"Transfer to Checking",-25,"Transfer")
^BankT(4) = $lb(10002345,66334,"Deposit to Savings",30,"Deposit")
-
^BankT is the name of the global. The name shown here is for illustrative purposes. In tables created using DDL, or in a persistent class with the USEEXTENTSET=1 parameter specified, InterSystems IRIS generates more efficient, hashed globals with names such as ^EW3K.Cku2.1. If a persistent class table does not specify USEEXTENTSET=1, then the global has a name of the format ^TableNameD. In the projected persistent class for an SQL table, the global is stored in the <DataLocation> element of the Storage class member. For example:
Storage Default { ... <DataLocation>^BankT</DataLocation> ... } -
The top-level global node’s value is the value of the highest subscript in the table, in this case 4. This integer subscript is used as the row ID.
-
Each global subscript is a $LIST containing the column values for one row. The order of element values is defined in the storage definition and usually corresponds to column order. In this example, the second element of each row corresponds to the TransactionDate column, which stores the data in $HOROLOG format (number of days since December 31, 1840).
Analytical Query Processing with Row Storage
To show how row storage can be less efficient for analytical processing, suppose you query the average size of all transaction amounts in the BankTransaction table:
SELECT AVG(ABS(Amount)) FROM Sample.BankTransactionWith this query, only the values in the Amount column are relevant. However, to access these values, the query must load each row into memory entirely, because the smallest unit of storage that InterSystems IRIS can read is a global node.

To check whether a query accesses each row individually, you can analyze the query execution plan. In the Management Portal, select System Explorer then SQL then Show Plan. Alternatively, use the EXPLAIN query SQL command. If the query plan includes a statement such as “Read master map ... looping on IDKEY”, then the query reads each row of the table, regardless of how relevant each column value is to the query.
To improve analytical query performance on tables with row storage, you can define indexes on fields that are frequently used for filtering in the WHERE clause. For more details, see Indexes for Different Storage Types.
Transaction Processing with Row Storage
To show how row storage can be efficient for transaction processing, suppose you insert a new row into the BankTransaction table.
INSERT INTO Sample.BankTransaction VALUES (10002345,TO_DATE('01 SEP 2022'),'Deposit to Savings',10.00,'Deposit')An INSERT operation creates a new $LIST global without needing to load any existing $LIST globals into memory.

Columnar Storage Layout
You can define an entire table as having columnar storage using either the InterSystems SQL DDL language or a persistent class.
Define Columnar Storage Table Using DDL
To define a table with a columnar storage in InterSystems SQL DDL, use the WITH STORAGETYPE = COLUMNAR after the column definitions in CREATE TABLE.
CREATE TABLE table ( column type, column2 type2 column3 type3) WITH STORAGETYPE = COLUMNAR
When a table defined to use columnar storage is created via DDL, the system considers the lengths of VARCHAR columns and reverts them to row storage when they are longer than 12 characters (the current internal string length limit for columnar storage). All other columns, including any additional VARCHAR columns with lengths of 12 or less, are still stored in columnar storage, resulting in a table with a mixed storage layout. When all columns are fit for columnar storage, every field is stored in the columnar layout, offering the highest-performance ingestion, querying, and most efficient storage.
This command creates a TransactionHistory table containing historical data of account transactions performed. It contains the same columns as the BankTransaction table created in the Row Storage Layout section. Note that in this example, the Description column is stored using row storage, while the other columns are stored using columnar storage.
CREATE TABLE Sample.TransactionHistory (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2),
Type VARCHAR(10))
WITH STORAGETYPE = COLUMNAR
Define Columnar Storage Table Using a Persistent Class
To create a columnar storage table by using a persistent class, set the STORAGEDEFAULT parameter to the value "columnar".
Parameter STORAGEDEFAULT = "columnar"
Unlike defining a table to use columnar storage through DDL, there is no check to validate that strings stored in this class meet the internal string length limit for columnar storage. As a result, you should exercise extra care with string lengths stored in tables defined to use columnar storage set with the STORAGEDEFAULT parameter, as you may encounter errors when ingesting and storing large numbers of unique strings that are longer than limit (which is 12 characters). Alternatively, you can set the MAXLEN of string-typed fields in your class to be 12 or less
The following persistent class defines a columnar storage table similar to the DDL-defined table created in the previous section. As with the BankTransaction table created in Define Row Storage Table Using a Persistent Class, this table defines a USEEXTENTSET parameter and bitmap extent index. For details on these settings, see Defining a Table by Creating a Persistent Class.
Class Sample.TransactionHistory Extends %Persistent [ DdlAllowed, Final ]
{
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
Property AccountNumber As %Integer;
Property TransactionDate As %Date;
Property Description As %String(MAXLEN = 10);
Property Amount As %Numeric(SCALE = 2);
Property Type As %String(VALUELIST = "-Deposit-Withdrawal-Transfer");
Index BitmapExtent [ Extent, Type = bitmap ];
}
You can declare any table as columnar. However, tables that use columnar as the default storage layout must specify either the Final class keyword or the NoExtent class keyword, with any immediate subclasses defined explicitly as Final.
As described earlier, the STORAGEDEFAULT parameter specifies which storage type InterSystems IRIS uses when generating the storage definition for a new table or column. However, some column types cannot be properly encoded into the optimized vector data types used for columnar storage. Serials, arrays, and lists are some types that cannot be properly encoded; a compilation error will arise when attempting to use a these data types with columnar storage. InterSystems IRIS automatically reverts to row storage in these cases:
-
A column type is incompatible with columnar storage. Streams, arrays, and lists are examples of incompatible types.
-
A column type is generally a poor fit for columnar storage. Strings longer than 12 characters are an example of a poor fit. In these cases, you can override the storage type by setting the STORAGETYPE = COLUMNAR clause on a column. For details, see the Mixed Storage Layout section. An example of when you might want to use columnar storage for strings longer than 12 characters anyway is when the cardinality of the strings is low. This means that there are only a few possible string values. If all the strings are different however, row storage is the better choice.
Columnar Storage Details
Global Structure
In a table with columnar storage, each column of a dataset is stored in a separate global. Within each column global, all row value elements are of the same data type and “chunked” into separate subscripts per 64,000 rows, similar to how $BIT values are stored. For example, if a table has 100,000 rows, then each column global has two subscripts. The first subscript contains the first 64,000 row values. The second subscript contains the remaining 36,000 row values. InterSystems IRIS uses a specialized vector encoding to efficiently store data of the same data type.
Suppose the TransactionHistory table defined in the previous section contains these records.
SELECT AccountNumber,TransactionDate,Description,Amount,Type FROM Sample.TransactionHistory| AccountNumber | TransactionDate | Description | Amount | Type |
|---|---|---|---|---|
|
10001234 |
02/22/2022 |
Deposit to Savings |
40.00 |
Deposit |
|
10001234 |
03/14/2022 |
Payment to Vendor |
-20.00 |
Withdrawal |
|
10002345 |
07/30/2022 |
Transfer to Checking |
-25.00 |
Transfer |
|
10002345 |
08/13/2022 |
Deposit to Savings |
30.00 |
Deposit |
You can optionally examine the global storage structure from the Management Portal by clicking System Explorer and then Globals. In the namespace containing the table, you can then select Show SQL Table Name and find the globals corresponding to your table. For more details, see Managing Globals.
The Data/Master global contains a subscript for each row and is used to reference data involving row operations. Each subscript row is empty, because the data is stored by column in separate globals. This code shows a sample Data/Master global.
^THist = 4
^THist is the name of the global. The name shown here is for illustrative purposes. In tables created using DDL, or in a persistent class with the USEEXTENTSET=1 parameter specified, InterSystems IRIS generates more efficient, hashed globals with names such as ^EW3K.B3vA.1. If a persistent class table does not specify USEEXTENTSET=1, then the global has a name of the format ^TableNameD. In the projected persistent class for an SQL table, the global is stored in the <DataLocation> element on the Storage class member. For example:
Storage Default
{
...
<DataLocation>^THist</DataLocation>
...
}
The table includes five additional globals, one per column, with names of the form, ^THist.V1, ^THist.V2, and so on. Each global stores a column of row values in a vector encoding, an internal data type designed to work with values of the same type and efficiently encode sparse data. The actual encoding is internal, but the Globals page and informational commands such as ZWRITE present a more readable format that describes:
-
the type of the data
-
the number of non-NULL elements in the column
-
the length of the vector
Because this table has fewer than 64,000 rows, each column global contains only a single subscript. The data in the globals shown here have been truncated for readability.
^THist.V1(1) = {"type":"integer", "count":4, "length":5, "vector":[,10001234,...]}
^THist.V2(1) = {"type":"integer", "count":4, "length":5, "vector":[,66162,...]}
^THist.V3(1) = {"type":"string", "count":4, "length":5, "vector":[,"Deposit to Savings",...]}
^THist.V4(1) = {"type":"decimal", "count":4, "length":5, "vector":[,40,...]}
^THist.V5(1) = {"type":"string", "count":4, "length":5, "vector":[,"Deposit",...]}
In this column global for a table with 200,000 rows, the data is spread across four global subscripts containing 64,000 + 64,000 + 64,000 + 8,000 elements. The count of elements is lower than the length, because the column includes NULL values.
^MyCol.V1(1) = {"type":"integer", "count":63867, "length":64000, "vector":[,1,1,1,,...]}
^MyCol.V1(2) = {"type":"integer", "count":63880, "length":64000, "vector":[1,1,1,,1,...]}
^MyCol.V1(3) = {"type":"integer", "count":63937, "length":64000, "vector":[1,1,1,2,2,...]}
^MyCol.V1(4) = {"type":"integer", "count":7906, "length":8000, "vector":[1,1,1,,2,...]}
String Collation with Columnar Storage
When a string-typed field is defined in a table that uses columnar storage by default, its collation will be defined as EXACT, unless otherwise specified. EXACT collation is used for string-typed fields even if the MAXLEN of the field exceeds the 12 characters, causing the field to revert to row storage.
Analytical Query Processing with Columnar Storage
To show how columnar storage can be efficient for analytical processing, suppose you query the average size of all transaction amounts in the TransactionHistory table:
SELECT AVG(ABS(Amount)) FROM Sample.TransactionHistoryWith columnar storage, this query loads only the Amount column global into memory and computes the average using the data in that column. None of the data from the other columns are loaded into memory, resulting in a more efficient query than if the data was stored in rows. Also, the optimized vector encoding comes with a set of dedicated vectorized operations that execute efficiently on an entire vector at a time, rather than on individual values. For example, calculating the sum of all elements inside a vector is several orders of magnitude faster than adding them up one by one, especially if each value needs to be extracted from a $list holding row data. Many of these vectorized operations leverage low-level SIMD (Single Instruction, Multiple Data) chipset optimizations.

You can check whether a query takes advantage of columnar storage efficiencies by analyzing the query execution plan. In the Management Portal, select System Explorer then SQL then Show Plan. Alternatively, use the EXPLAIN query SQL command. If the query plan includes statements such as "read columnar index", "apply vector operations" or "columnar data/index map", then the query is accessing data from column globals.
Transaction Processing with Columnar Storage
To show how columnar storage can be less efficient for transaction processing, suppose you insert a new row into the TransactionHistory table.
INSERT INTO Sample.TransactionHistory VALUES (10002345,TO_DATE('01 SEP 2022'),'Deposit to Savings',10.00,'Deposit')Because row data is distributed across all column globals, an INSERT operation must load the last chunk for each of these globals into memory to perform the insert.

Because inserts into columnar storage layouts can be so memory inefficient, perform them infrequently or in bulk, such as by using the LOAD DATA command. InterSystems IRIS includes optimizations that buffer INSERTs for columnar tables in memory before writing chunks to disk.
Mixed Storage Layout
For additional flexibility, you can define a table as having a mixture of row and columnar storage. In these tables, you specify an overall storage type for the table and then set specific fields as having a different storage type.
Mixed storage can be useful in transaction-based tables that have a few columns that you want to perform analytical queries on, such as fields that are often aggregated. You can store the bulk of the table data in rows, but then store the columns you frequently aggregate in the columnar format. Columns that are usually returned as is in row-level query results, without any filtering or grouping, might also be a good fit for row storage to save on the cost of materializing those rows before including them in the result. This enables you to perform transactional and analytical queries on a single table.
Define Mixed Storage Using DDL
To define a table with mixed storage in InterSystems SQL DDL, specify the WITH STORAGETYPE = ROW or WITH STORAGETYPE = COLUMNAR clause on individual columns in a CREATE TABLE command.
This syntax creates a table with the default, row-based storage layout but with the third column using columnar storage.
CREATE TABLE table ( column type, column2 type2 column3 type3 WITH STORAGETYPE = COLUMNAR)
This syntax creates a table with a column-based storage layout but with the third column stored in row layout.
CREATE TABLE table ( column type, column2 type2 column3 type3 WITH STORAGETYPE = ROW) WITH STORAGETYPE = COLUMNAR
This CREATE TABLE command creates a BankTransaction table that stores all data in row layout except for the data in the Amount column, which uses columnar storage.
CREATE TABLE Sample.BankTransaction (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2) WITH STORAGETYPE = COLUMNAR,
Type VARCHAR(10))
Define Mixed Storage Table Using a Persistent Class
To create a table with mixed storage by using a persistent class, specify the STORAGEDEFAULT parameter on the individual properties. Valid values are "columnar" and "row" (default).
Property propertyName AS dataType(STORAGEDEFAULT = ["row" | "columnar"])
This persistent class shows the definition of a columnar storage table. This table is similar to the DDL-defined table created in the previous section.
Class Sample.BankTransaction Extends %Persistent [ DdlAllowed, Final ]
{
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
Property AccountNumber As %Integer;
Property TransactionDate As %Date;
Property Description As %String(MAXLEN = 100);
Property Amount As %Numeric(SCALE = 2, STORAGEDEFAULT = "columnar");
Property Type As %String(VALUELIST = "-Deposit-Withdrawal-Transfer");
Index BitmapExtent [ Extent, Type = bitmap ];
}
Mixed Storage Details
Global Storage
A table with mixed storage uses a combination of global storage structures, where:
-
Data with a row storage layout is stored in $list format in the Data/Master global.
-
Data with a columnar storage layout is stored in a vector encoding in separate column globals.
Consider this BankTransaction table:
Class Sample.BankTransaction Extends %Persistent [ DdlAllowed ]
{
Parameter STORAGEDEFAULT = "row";
Parameter USEEXTENTSET = 1;
Property AccountNumber As %Integer;
Property TransactionDate As %Date;
Property Description As %String(MAXLEN = 100);
Property Amount As %Numeric(SCALE = 2, STORAGEDEFAULT = "columnar");
Property Type As %String(VALUELIST = "-Deposit-Withdrawal-Transfer");
Index BitmapExtent [ Extent, Type = bitmap ];
}
Notice that it is mostly similar to the example in Define Mixed Storage Table Using a Persistent Class, but uses columnar storage for the Amount column and row storage for everything else. The sample logical abstraction of the table data, shown here, is identical to the tables shown in Row Storage Details and Columnar Storage Details.
SELECT AccountNumber,TransactionDate,Description,Amount,Type FROM Sample.BankTransaction| AccountNumber | TransactionDate | Description | Amount | Type |
|---|---|---|---|---|
|
10001234 |
02/22/2022 |
Deposit to Savings |
40.00 |
Deposit |
|
10001234 |
03/14/2022 |
Payment to Vendor |
-20.00 |
Withdrawal |
|
10002345 |
07/30/2022 |
Transfer to Checking |
-25.00 |
Transfer |
|
10002345 |
08/13/2022 |
Deposit to Savings |
30.00 |
Deposit |
In the Management Portal, the Globals page shows how this data is stored. The Data/Master global stores the data for the rows. This format is similar to the format shown in Row Storage Details, but the data for the Amount column is not present.
^BankT = 4
^BankT(1) = $lb(10001234,66162,"Deposit to Savings","Deposit")
^BankT(2) = $lb(10001234,66182,"Payment to Vendor ABC","Withdrawal")
^BankT(3) = $lb(10002345,66320,"Transfer to Checking","Transfer")
^BankT(4) = $lb(10002345,66334,"Deposit to Savings","Deposit")
The table includes an additional global that stores the Amount column data. This format is similar to the format shown in Columnar Storage Details.
^BankT.V1(1) = {"type":"decimal", "count":4, "length":5, "vector":[,40,-20,-25,30]}
The table metadata contains information about column order. InterSystems IRIS uses this information to construct the relational table using the data stored in the row and column globals.
String Collation
When mixing storage layouts, any string-typed field that uses columnar storage, either by using the table’s default storage or as an explicit setting on a particular field, is defined to have EXACT collation.
Analytical Query Processing with Mixed Storage
The efficiency of analytical queries depends on the data you access. Consider the BankTransaction table created in the previous section, where only the Amount column uses columnar storage. Querying the average size of all transaction amounts is efficient, because only the Amount column is accessed.
SELECT AVG(ABS(Amount)) FROM Sample.BankTransactionIn this diagram, the Amount column is separated from the columns that are stored in rows.

However, if a query performed additional aggregations on other columns stored as rows, the performance gains might not be as noticeable.
Transaction Processing with Mixed Storage
If a mixed storage table requires frequent updates and insertions, performance can be slower that pure row storage, but not as slow as pure columnar storage. For example, suppose you insert a new row into the BankTransaction table that uses columnar storage only for the Amount column.
INSERT INTO Sample.BankTransaction
VALUES (10002345,TO_DATE('01 SEP 2022'),'Deposit to Savings',10.00,'Deposit')The INSERT operation does not load any existing row globals, but to insert the new Amount value, the entire last chunk of the Amount column global must be loaded into memory. Depending on your data, this overhead on transaction processing might be preferable to maintaining separate tables for transactions and analytics.

Indexes on Storage Layouts
The type of storage format that you choose does not preclude you from defining indexes on your tables. The benefits gained from indexes can vary depending on the storage format.
Indexes on Row Storage Layouts
As shown in the Analytical Processing with Row Storage section, filter and aggregate operations on columns in tables with a row storage layout can be slow. Defining a bitmap or columnar index on such tables can help improve the performance of these analytical operations.
A bitmap index uses a series of bitstrings to represent the set of ID values that correspond to a given indexed data value. This format is highly compressed and can reduce the number of rows that you look up. Also, different bitmap indexes can be combined using Boolean logic for efficient filtering involving multiple fields or field values. For more details on working with bitmaps, see Bitmap Indexes.
Using the BankTransaction table from earlier sections, suppose you create this bitmap index on the Type column:
CREATE TABLE Sample.BankTransaction (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2),
Type VARCHAR(10))
CREATE BITMAP INDEX TypeIndex
ON Sample.BankTransaction(Type)
Suppose you then perform an aggregate query in which you limit rows based on one of the transaction types.
SELECT AVG(ABS(Amount)) FROM Sample.BankTransaction WHERE Type = 'Deposit'The bitmap index ensures that the query iterates only the rows for the selected transaction type, as shown by this diagram.
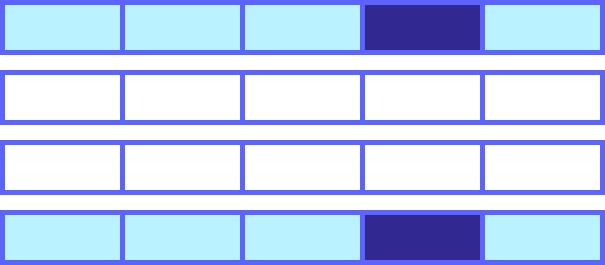
However, as shown by this diagram, after using the bitmap index to find eligible rows, InterSystems IRIS still needs to fetch the entire row even if you need only a single element per row. If your table has millions of rows, even a filtered set of rows can incur a heavy performance cost.
Alternatively, you can define a columnar index on a column that is frequently queried. A columnar index stores the same vectorized column data described in Columnar Storage Details. Use this index to improve analytical query performance on row storage tables at the expense of the storage costs of an additional index.
To define a columnar index using InterSystems SQL DDL, use the CREATE COLUMNAR INDEX syntax of CREATE INDEX:
CREATE COLUMNAR INDEX indexName ON table(column)
To define a columnar index in a persistent class, specify the type = columnar keyword on the index you define:
Index indexName ON propertyName [ type = columnar ]
Using the BankTransaction table again, suppose you create a bitmap index on the Type column and a columnar index on the Amount column:
CREATE TABLE Sample.BankTransaction (
AccountNumber INTEGER,
TransactionDate DATE,
Description VARCHAR(100),
Amount NUMERIC(10,2),
Type VARCHAR(10))
CREATE BITMAP INDEX TypeIndex
ON Sample.BankTransaction(Type)
CREATE COLUMNAR INDEX AmountIndex
ON Sample.BankTransaction(Amount)
The aggregate query from earlier now combines the use of both indexes to access only the data being queried. First the query looks up which rows to access based on the TypeIndex bitmap index. Then it accesses the Amount values for those rows from the AmountIndex columnar index.
SELECT AVG(ABS(Amount)) FROM Sample.BankTransaction WHERE Type = 'Deposit'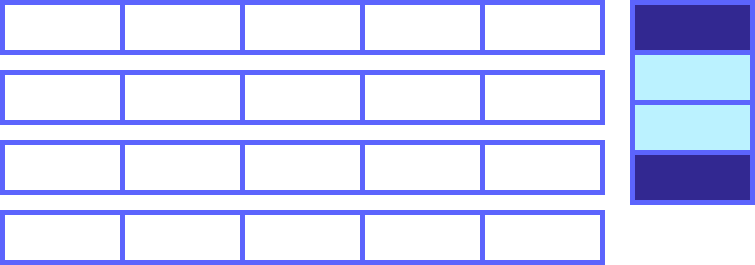
Indexes on Columnar Storage Layouts
If the primary purpose of the columnar storage table is aggregation and filter operations, then additional indexes might not provide many performance gains. For example, although a bitmap index can improve filtering performance, the performance gains might not justify the additional storage they take up and the ingestion overhead they cause. If your query workload involves lookups on highly selective fields or unique keys, then defining regular indexes might still be worthwhile. Determining whether such indexes are worth defining requires query experimentation and analyzing the trade-offs. For more details on defining indexes, see Defining and Building Indexes.
Suggested Application of Row and Columnar Storage
While InterSystems has no prescriptive formula for whether to use columnar or row-wise storage in your tables, there are general guidelines that may help you when defining the your InterSystems SQL schema structure. In general, adhere to the following guidelines:
-
If your InterSystems IRIS SQL tables contain less than one million rows, there is no need to consider columnar storage. The benefits of vectorized storage are unlikely to make a significant difference on smaller tables.
-
Use the default row-wise storage layout for applications that leverage InterSystems SQL or Objects, such as a transaction processing application. Most queries issued for applications or programmatic transactions only retrieve or update a limited number of rows and rarely use aggregate functions. In such cases, the benefits offered by columnar storage and vectorized query processing do not apply.
-
If such an application employs operational analytics, add columnar indexes if the performance of analytical queries is not satisfactory. In these cases, look for numeric fields used in aggregations, like quantities or currencies, or fields with high cardinality used in range conditions, like timestamps. Columnar indexes can be used in conjunction with bitmap indexes to avoid excessive read operations from the master map or regular index maps.
-
Use the columnar storage layout if you are deploying an InterSystems IRIS SQL schema for analytical use cases. Star schemas, snowflake schemas, or other de-normalized table structures, as well as broad use of bitmap indexes and batch ingestion, are good indicators of these use cases. Analytical queries benefit the most from columnar storage when they aggregate values across rows. When defining a columnar table, InterSystems IRIS automatically reverts to a row-wise storage layout for columns that are not a good fit for columnar storage, including streams, lengthy strings, or serial fields. InterSystems IRIS SQL fully supports mixed table layouts and uses vectorized query processing for eligible parts of the query plan. On columnar tables, you may omit a bitmap index, as their value on such tables is limited.
These suggestions may be impacted by both data-related factors and the environment in which your application runs. Therefore, InterSystems recommends that customers tests different layouts in a representative setup to determine which layouts will provide the best performance.