
Add Data Nodes and Rebalance Data
Add Data Nodes and Rebalance Data
InterSystems IRIS sharding is designed for scalability and elasticity. As described in Planning an InterSystems IRIS Sharded Cluster, the number of data nodes you include in a cluster when first deployed is influenced by a number of factors, including but not limited to the estimated working set for sharded tables and the compute resources you have available. Over time, however, you may want to add data nodes for a number of reasons, for example because the amount of sharded data on the cluster has grown significantly, or a resource constraint has been removed. Data nodes can be added using any of the deployment methods described in Deploying the Sharded Cluster, automated or manual.
As described in Overview of InterSystems IRIS Sharding, sharding scales query processing throughput by decomposing queries and executing them in parallel on all of the data nodes, with the results merged, aggregated, and returned as full query results to the application. Generally speaking, the greater the amount of sharded data stored on a data node, the longer it will take to return results, and overall query performance is gated by the slowest data node. For optimal performance, therefore, storage of sharded data should be roughly even across the data nodes of the cluster.
This will not be the case after you add data nodes, but rebalancing the cluster’s sharded data across all of the data nodes restores this roughly even distribution. A cluster can be rebalanced without interrupting the its operation.
The process of adding data nodes and rebalancing data is described in the following example:
-
After you add data nodes to a cluster, the rows of existing sharded tables remain where they were on the original nodes until you rebalance.
A Data Node is Added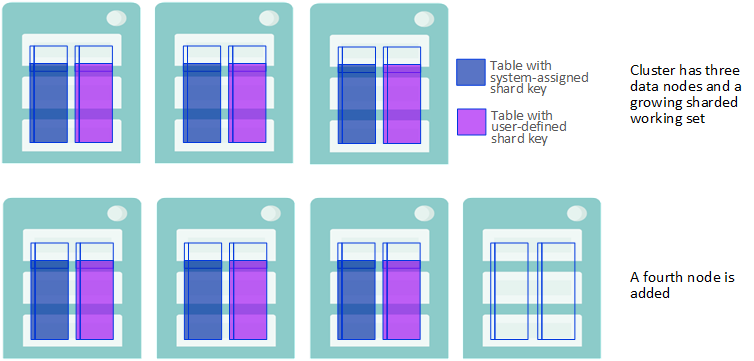
-
When sharded data is added to the scaled cluster, in the form of either rows inserted into a previously existing table or new tables created and loaded with data, their storage depends on each table’s shard key:
-
If the table has a system-assigned shard key (SASK), the new rows are stored evenly across all of the data nodes, including the new nodes.
-
If the table has a user-defined shard key (UDSK), the new rows are stored evenly across the original set of data nodes only, and not on the newly-added nodes. (If there were no existing UDSK tables before the new nodes were added, however, rows in new UDSK tables are distributed across all data nodes.)
New Data is Stored Based on the Shard Key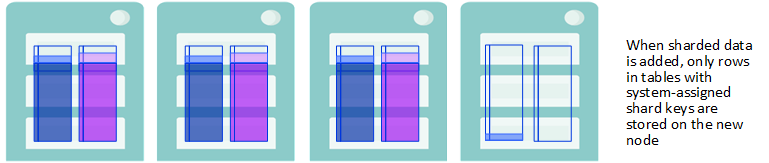
-
-
To take full advantage of parallel query processing on the cluster after adding data nodes, rebalance the sharded data stored on the cluster and enable balanced storage of data added to the cluster in the future.
Rebalancing Stores Sharded Data Evenly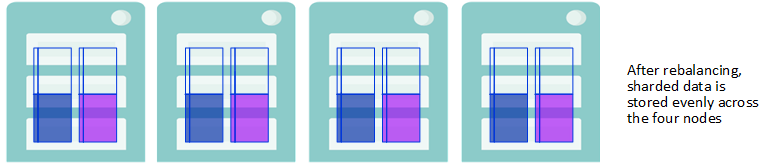
-
After rebalancing, both rows added to existing tables and the rows of newly created tables are also distributed across all data nodes, regardless of shard key. Thus, once you have rebalanced, all sharded data — in existing tables, rows added to existing tables, and new tables — is evenly distributed across all data nodes.
New Sharded Date is Stored Evenly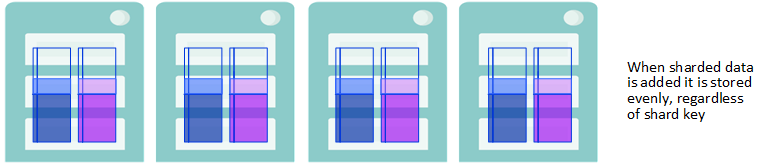
You can initiate the rebalancing operation in one of two ways:
-
Using the REBALANCE dialog, displayed by clicking Rebalance on the Management Portal’s Configure Node-Level page (System Administration > Configuration > System Configuration > Sharding > Configure Node-Level).
-
Using the $SYSTEM.Sharding.Rebalance()Opens in a new tab API call.
The Class Reference documentation for $SYSTEM.Sharding.Rebalance()Opens in a new tab explains the parameters you can specify using either interface, as well as the detailed mechanics of the rebalancing of sharded data among the data nodes.
All operations on sharded tables are permitted during a rebalancing operation with the exception of JDBC batch inserts to sharded tables (or any bulk load utility that utilizes brokered JDBC batch inserts), which return an error if attempted. An ongoing rebalancing operation may have a small negative effect on query performance and, to a lesser extent, on other operations including updates, inserts, and deletes; creating, altering and dropping tables; and assigning new shards.
If performance is of sufficient concern, you can specify a time limit on the operation, so that it can be scheduled during a low-traffic period or even a maintenance window. When the time limit is reached, the rebalancing operation (if not already complete) stops moving data (although some cleanup tasks may continue for a short time); if there remains data to be rebalanced, you can at the time of your choosing initiate another rebalancing operation, which picks up where the previous one left off. By using this approach you can fully rebalance the cluster with a series of scheduled operations of whatever length suits your needs.
When using the API call, you can also specify the minimum amount of data to be moved by the call; if it is not possible to move that much data within the specified time limit, no rebalancing occurs. Bear in mind that after you have added data nodes, you maximize performance by rebalancing the data.